


AIへのコスト増とLLMflation
2026年6月、AnthropicはMythosと同等レベルの最上位AIモデルとしてFable 5を一般公開しました。わずか数日後に同社は一般提供を停止してしまいましたが、筆者はその数日間で運よくFable 5を試すことができ、その威力を肌で感じることができました。 これまでのどのモデルよりも賢く、複雑なタスクに抽象的なプロンプトを投げても、こちらの意図をうまく汲み取り、そのタスクを正確に実行してくれる感覚がありました。一方で、トークンの消費量も桁違いでした。Claude CodeでFable 5を数時間触っただけで、午前中のうちにCurrent Sessionの上限に達してしまいました。この体験からも分かるように、モデルが賢くなるほど、そのトークン消費量は増え続けています。
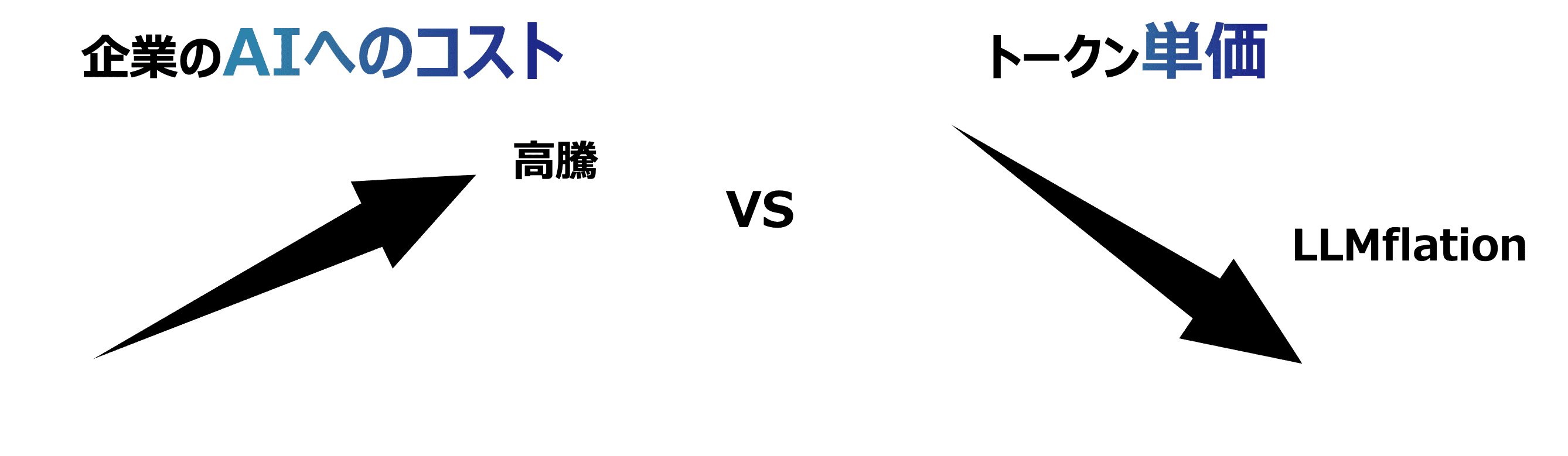
ところが、同じ性能を得るためのトークン単価そのものは、急速に下がり続けています。a16zの記事[1]によると、2021年11月にGPT-3が公開された当時、GPT-3はMMLUと呼ばれるAIのベンチマークでスコア42点を達成できる唯一のモデルでしたが、そのコストは100万トークンあたり60ドルでした。それが当該記事の執筆時点の2024年では、同じスコアを最も安く出せるモデルはLlama 3.2 3Bとなり、100万トークンあたりわずか0.06ドルにまで下がりました。3年で1,000分の1です。この下落速度は、PC革命期の計算コストや、ドットコム期の通信帯域コストの下落をも上回るといいます。当該記事は、この現象を「LLMflation」と名付けました。
この事実だけを見れば、AIのコストは時間が経つにつれて下落していきそうにも思えます。つまり、何もしなくても、来年には同じ仕事がより低いコストでできるようになりそうです。しかし実際には、多くの組織でその逆の動きが起きています。つまり、多くの企業で生成AIへの支払額が増加し、その負担は徐々に重くなっているのです。この「AIは安くなっているはずなのに、コストは増えていく」という逆説は、トークン単価の問題として捉えているかぎりうまく説明できません。本記事では、この逆説の背景にある原因を整理し、企業が考えるべき生成AIのコスト最適化の方針について考えます。
コスト増加の背景

ある水準に到達するための生成AIの単価は、LLMflationの議論からも分かるように減り続けています。では、なぜ企業が生成AIに支払うコストは上昇し続けているのでしょうか。当たり前ですが、単価の下落と支出の増加が両立するのは、消費量が単価の下落を上回る速度で増えているからです。そしてこの消費量の増加は、利用者数や利用場面が増えたという単純な話だけではなく、生成AIの使われ方そのものの変化に根ざしています。ここでは4つの要因について触れます。
要因1:フロンティアの追随
第1に、ほとんどの組織は「同じ性能を安く使う」のではなく「最新の性能を使い続ける」選択をしていることが背景にあります。
LLMflationは、あくまで「固定された性能水準」のコスト低下を示すものです。しかし現場では、先のFable 5の話のように、新しいモデルが出るたびにそれまで不可能だったタスクが可能になり、ユーザはそちらへ移っていきます。フロンティアモデルの単価は世代を超えてもそれほど下がらず、むしろ最上位モデルは高止まりするため、フロンティアを追い続けるかぎり、単価下落の恩恵は受けられません。
要因2:トークン消費の推奨
第2に、近年広がる「トークン・マキシマム(Token-Maximizing)」と呼ばれる考え方があります。
これは、トークン消費量そのものをAIの活用度や従業員の生産性を測る指標として捉え、それを積極的に最大化していこうとするトレンドを指します。背景にあるのは、生成AIを使いこなしている人ほどトークンを多く消費するはずだ、ならばその消費量はAIの活用度や生産性の代理指標になるのではないか、という発想です。実際、社内のAI利用を促進したい立場からすれば、「消費量が増えている」というのは、AI利活用が現場に浸透している一種の証左にも見えます。
要因3:推論モデルによる消費
第3に、2024年末以降に主流となった推論モデル(Large Reasoning Models)の存在があります。
多くのモデルは、回答の前に長い思考の連鎖(CoT: Chain of Thought)を生成することで、複雑なタスクの性能を大きく引き上げました。しかしこれは、課金対象となるトークンを回答そのものの何倍も消費することを意味します。1回のLLMの呼び出しの「裏側」で消費されるトークン量が、モデルの世代交代によって桁単位で増えたのです。つまり、トークン単価が下がる一方で、1タスクあたりのトークン消費量は、モデルの賢さと引き換えに増えているのです。
要因4:AIエージェントによる消費
第4に、そして実務上最も重要なのが、AIエージェントの台頭です。
従来のチャットボットでは、1つの質問は1回のLLM呼び出しで完結していました。しかしAIエージェントは、観測・推論・行動のループを何十回も繰り返しながらタスクを遂行します。「特徴量から、行動へ」の記事でも触れたように、エージェントの振る舞いは単一の予測ではなく「軌跡」として展開します。コストの観点から見れば、これは1タスクあたりのLLM呼び出し回数が増えることを意味します。しかも各ステップでは、システムプロンプト、ツール定義、それまでの会話履歴という長大なコンテキストが、毎回入力トークンとして再送信されます。
Cost-of-Pass
企業や個人が支払う生成AIのコストは、利用回数や利用場面の増加といった単純な話だけでなく、以上のような生成AIの使われ方やトレンドが相まって増加していると言えます。それでは、このコストをどのように最適化していけば良いのでしょうか。以下では、Stanfordの研究チームが2025年に提唱したCost-of-Passというフレームワーク[2]を頼りに、コスト最適化の方向性を考えていきます。
「安いが間違いの多いモデル」はリトライ等でトークンを無駄に消費する可能性があるため、「高いが確実なモデル」のほうが最終的なコストは安い場合もあります。この直観を定式化したものがCost-of-Passです。 より具体的には、Cost-of-Passとは「正解を1件得るための期待金銭コスト」です。1回の推論コストを正答率で割ることで算出されます。例えば、1回の推論に0.01ドルかかり正答率が50%のモデルなら、正解1件あたりのコストは0.02ドル(=0.01ドル÷0.5)です。Stanfordの研究チームでは、利用可能なモデル群の中で達成できる最小のCost-of-Passを「フロンティアCost-of-Pass」と定義し、その推移を追跡しています。その結果、以下の2点の示唆が得られました。
第1に、最適なモデルはタスクの種類によって異なるという点です。Stanfordの研究チームによれば、基本的なタスクでは軽量モデルが、知識集約型のタスクでは大規模モデルが、数学等の複雑な定量タスクでは推論モデルが、それぞれ最もCost-of-Passを低く抑えました。推論モデルはトークン単価が高くても、複雑な問題では正答率の高さがそれを上回り、正解1件あたりでは最も安くなります。逆に、基本的なタスクでは、推論モデルよりも軽量モデルのほうがCost-of-Passは安くなります。
第2に、推論時の小手先のテクニックは経済的に割に合わないことが多いという結果です。同論文は、多数決(複数回AIを使って多数決を取る方法)や自己修正(AIの回答をAI自身に見直させる方法)といった一般的な推論テクニックのCost-of-Passを検証し、わずかな性能向上のために投じるコストが見合わないケースが大半であることを示しました。そして全体として、コスト効率の改善を牽引してきた主因は、こうした推論時の工夫ではなく、モデル自体の世代交代だったと結論づけています。大半のタスクでは、推論テクニックを駆使して微調整するよりも、新世代モデルへの移行を機動的に行える体制を整えるほうが、コスト効率への寄与は大きいということです。
Cost-of-Passからの示唆を踏まえた戦略

では、以上2点の示唆から、企業が取るべき戦略は何になるでしょうか。ここでは3つに分けて説明します。
モデルルーティング・カスケード
1つ目は、モデルのルーティングおよびカスケードの検討です。
実務上のタスクの難易度は、タスクの内容によって偏っています。単純な質問にFable 5を使うことは、直感的にもCost-of-Passを押し上げます。実は、業務上のタスクの大半は軽量モデルで十分に処理でき、フロンティアモデルの能力を必要とするのは一部の業務に過ぎないこともあります。このことを前提に、リクエストの難易度を判定して適切なモデルへ振り分けるのが、ルーティング(routing)あるいはカスケード(cascading)と呼ばれるアプローチです。
例えば、2024年のRouteLLMは、人間の選好データから「このクエリには強いモデルが必要か」を学習するルーターを構築し、GPT-4の性能の95%を維持しながら、ベンチマークによっては85%以上のコスト削減を実現しました[3]。また、2023年のFrugalGPTは、安価なモデルから順に試し、回答の信頼度が低い場合のみ上位モデルへ回すカスケード戦略によって、GPT-4と同等の性能を最大98%低いコストで達成できることを示しました[4]。
ルーティングやカスケードは、特定モデル(例えば、Fable 5)だけでの最適化ではなく、複数のモデル群のポートフォリオを運用する仕組みそのものです。仮に新しいモデルが出れば、ポートフォリオの構成を入れ替えるだけでその恩恵を取り込むことができます。このように、単一モデルへの依存を前提とした設計から、複数モデルの使い分けを前提とした設計へ変更することは、コスト戦略であると同時に、特定ベンダーへのロックインを避けるアーキテクチャ戦略でもあります。Fable 5が一般公開後すぐに公開停止になったことを考えると、1つのモデルに依存し過ぎることはリスクにもなります。この「モデル群のポートフォリオを運用する仕組み」に変更することはシステム全体のレジリエンスを強化することにも繋がります。
思考量の制御
2つ目は、推論モデルの「考えすぎ」への対処です。
一部の研究領域では、タスクの難易度に応じて思考の長さを制御する手法が数多く提案されています[5]。実務レベルでも、主要APIが提供する思考トークンの予算設定を使い、単純なタスクには短い思考を、複雑なタスクには長い思考を割り当てるだけで、品質をほぼ維持したままトークン消費を大きく削減できる場合があります。これは、ルーティングの考え方を、モデル選択のレベルからモデル内部の思考量のレベルへ拡張したものと捉えられます。
コストの可視化
3つ目は、コストの可視化です。
推論時にどれだけのコストを、どのタイミングでかけているのかを可視化し、その上で構成ごとのCost-of-Passを算出して可視化することが重要です。それにより、細かなアーキテクチャの違い(多数決方式か、自己修正方式か等)が実際にどの程度Cost-of-Passに寄与しているのかが見えてきます。そして場合によっては、その細かな工夫を捨てる勇気も必要になります。家計簿アプリを使うと、自らの支出が見える化され、無駄な支出が減るというのはよくある話ですが、AIへの投資も見える化することで投資対効果が見合わないコストを削減するきっかけになります。
なお、コストの可視化にあたり、仮にAIエージェントを動かしているのであれば、その一連の動作のうちどのステップが全体のコストを膨らませているのかを特定する必要があります。これは「特徴量から、行動へ」の記事と同じ話です。AIエージェントの説明可能性のためには、実行ログ・状態更新・ツール呼び出しを記録するオブザーバビリティが前提になると記事では議論しています。コスト管理に必要なのも、まさに同じ軌跡全体のデータです。各ステップのトークン消費を軌跡に紐づけて記録すれば、「なぜ失敗したのか」と「なぜこんなにコストがかかったのか」は、同じ基盤の上で答えられる問いになります。実際、エージェントのコスト超過の多くは、失敗パターンと表裏一体です。誤ったツール選択によるやり直し、状態の見失いによる堂々巡り、エラー後のリトライ——これらは品質の問題であると同時に、コストの問題でもあります。
※ その他、生成AIを用いたシステムの一般的なコスト削減方法として、プロンプトキャッシングとバッチ処理があります。前者は、システムプロンプトやツール定義、参照ドキュメントといった繰り返し送信される部分をプロバイダー側にキャッシュさせる手法で、キャッシュにヒットするとトークン単価が安価になります。エージェントのように同一コンテキストを何十回も再送するワークロードでは、その効果は劇的です。後者は、即時性を要しない処理(夜間の一括分類、定期レポート生成など)をバッチAPIへ逃がす手法で、多くのAIプロバイダーで半額程度の単価が適用されます。リアルタイム性が本当に必要な処理はどれかという業務要件の整理が、そのままコスト削減につながります。
おわりに
トークン単価の暴落と、企業の生成AIへの支出の増加は、矛盾ではありません。AIが担う仕事の範囲が単価の下落を上回る速度で広がっていることに加え、生成AIの使われ方そのものに根ざした当然の帰結とも言えます。このトレンドは、今後もしばらく変わらないように思えます。だからこそ、各企業はこの支出を価値へ正しく結びつけるべく、コスト最適化に取り組むことが重要になります。
AIエージェントを「作って終わり」にせず、評価・監督・説明責任、そしてコスト管理まで含めて業務に組み込むこと。Velcore Consultingでは、そのための設計・実装・運用支援を行っています。
参照文献
- [1] Appenzeller, G. (2024). Welcome to LLMflation – LLM Inference Cost Is Going Down Fast. Andreessen Horowitz. https://a16z.com/llmflation-llm-inference-cost/
- [2] Erol, M. H., El, B., Suzgun, M., Yuksekgonul, M., & Zou, J. (2025). Cost-of-Pass: An Economic Framework for Evaluating Language Models. arXiv:2504.13359. https://arxiv.org/abs/2504.13359
- [3] Ong, I., Almahairi, A., Wu, V., et al. (2024). RouteLLM: Learning to Route LLMs with Preference Data. ICLR 2025. arXiv:2406.18665. https://arxiv.org/abs/2406.18665
- [4] Chen, L., Zaharia, M., & Zou, J. (2023). FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv:2305.05176. https://arxiv.org/abs/2305.05176
- [5] Sui, Y., Chuang, Y.-N., Wang, G., et al. (2025). Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models. arXiv:2503.16419. https://arxiv.org/abs/2503.16419
生成AIのコスト最適化から、評価・監督・運用までを含めたAI活用の設計・実装・運用支援について、Velcore Consulting がご相談を承っています。
お問い合わせ